
はじめに
Twitterのホットトピック取得については、こちらで紹介しました。
今回は上記記事の手法でホットトピックを取得し、2017/6/17にあったAKBの総選挙の際のトピック遷移を可視化してみました。
話題ワードTop20から、24時間分のTop10を10分毎に表示しています。
大きさは、ランキング上位なものほど文字のサイズを大きくしています。
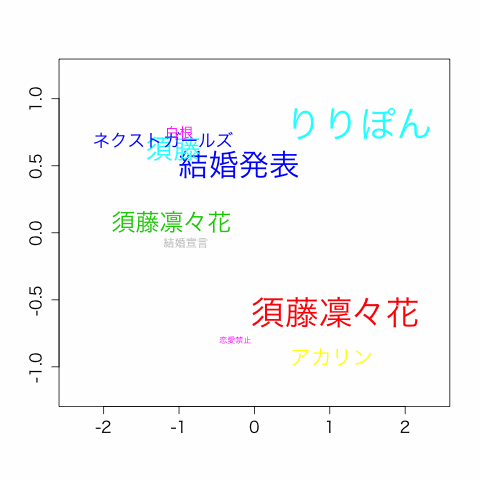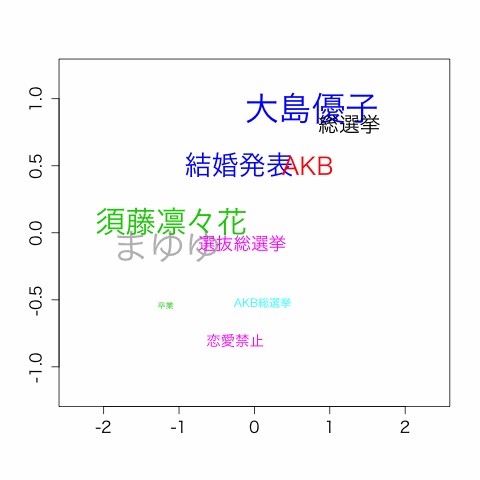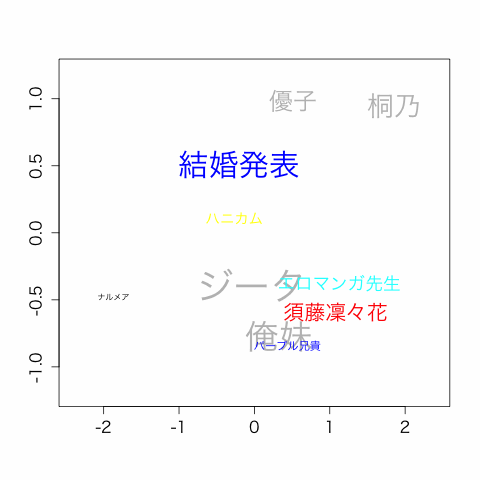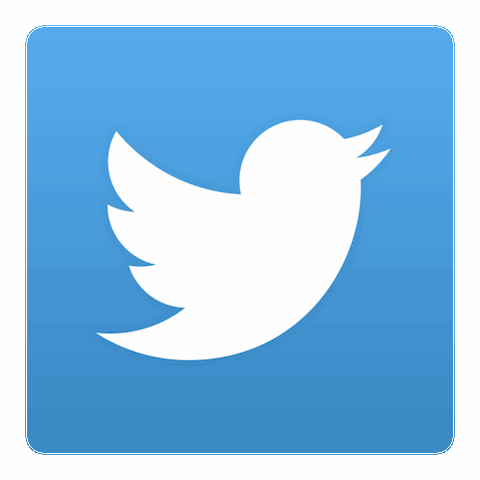
この画像を作成するにあたって行った、
文字列 → 数値 への変換について当記事では紹介します。
ポイント
同じワードは同じ位置に表示させたいため、同じ文字列から同じx座標、y座標を生成する必要があります。
今回は、R言語にて Message Digest 5 を用いました。
パッケージをインストールすると、
> library(openssl) > md5("hoge") [1] "ea703e7aa1efda0064eaa507d9e8ab7e"
のように 文字列"hoge"から"ea703e7aa1efda0064eaa507d9e8ab7e"といったハッシュ値が生成されます。
文字列"hoge"からx座標とy座標を生成するために、md5で生成された文字列から[a-z]を抜いて、整数に変換しています。
y座標は、文字列を反転させて(hogeならegoh)同じ処理をしています。
> as.integer(substr(gsub("[a-z]","",md5("hoge")),0,5)) [1] 70371 > as.integer(substr(paste(rev(strsplit(gsub("[a-z]","",md5("hoge")),NULL)[[1]]),collapse=""),0,5)) [1] 78970
あとは、上で取得した座標位置に text 関数 で 文字を貼付けてplot画像を生成しました。
文字の色も、md5の値を使って文字列から一意になるようにしています。*1
一応、ソースコード全文は以下に掲載しておきます。
ひらがなをplotに図示するために par(family="HiraKakuProN-W3") という設定を入れています。
library(openssl) tweet_mat <- matrix(scan("上位20位がカンマ区切りで記載されているファイルパス",what=character(),sep=","),nrow=20) par(family="HiraKakuProN-W3") for (i in 1:144) { plot(-10,10,xlab="",ylab="",xlim=c(-2.4,2.4),ylim=c(-1.2,1.2)) for (j in 1:10) { tweet_x <- 2-4*as.integer(substr(gsub("[a-z]","",md5(tweet_mat[j,i])),0,5))/100000 tweet_y <- 1-2*as.integer(substr(paste(rev(strsplit(gsub("[a-z]","",md5(tweet_mat[j,i])),NULL)[[1]]),collapse=""),0,5))/100000 tweet_col <- as.integer(substr(gsub("[a-z]","",md5(tweet_mat[j,i])),0,5))%%8 + 1 text(x=tweet_x,y=tweet_y,labels=tweet_mat[j,i],cex=(10-j)/5+0.5,col=tweet_col) } filename <- paste("./hoge/file",i,".png",sep="_") dev.copy(png,file=filename) dev.off() }
また、元ファイルがSJISでない場合も文字化けする可能性があります。
# nkf -g test.csv
で文字コードを確認し
# nkf -s --overwrite test.csv
で必要に応じて変換してください。
以上です。
*1:また、気が向いたら md5 での 文字列→数字 の生成部分が乱数のように機能しているのか検証してみたいです。